
In our previous blog post we discussed how advanced AI technology – driven by Large Language Models – can be used for automatic redaction of sensitive information. We mentioned that very high accuracy can be achieved with such technology.
In this post we will show that the latter is indeed the case.
Recall
We already addressed accuracy of AI-driven data extraction and redaction in a blog post in January: Smart VDRs – It is all about Accuracy. We discussed how “Recall” is of paramount importance. Without a high recall, there is no point to automated redaction or key data extraction: the tools need to be able to find all the terms that need to be redacted/extracted.
Let’s focus on the redaction use case again. Here are the test results from one of the experiments we used to test the Imprima LLM-driven Smart Redaction technology.
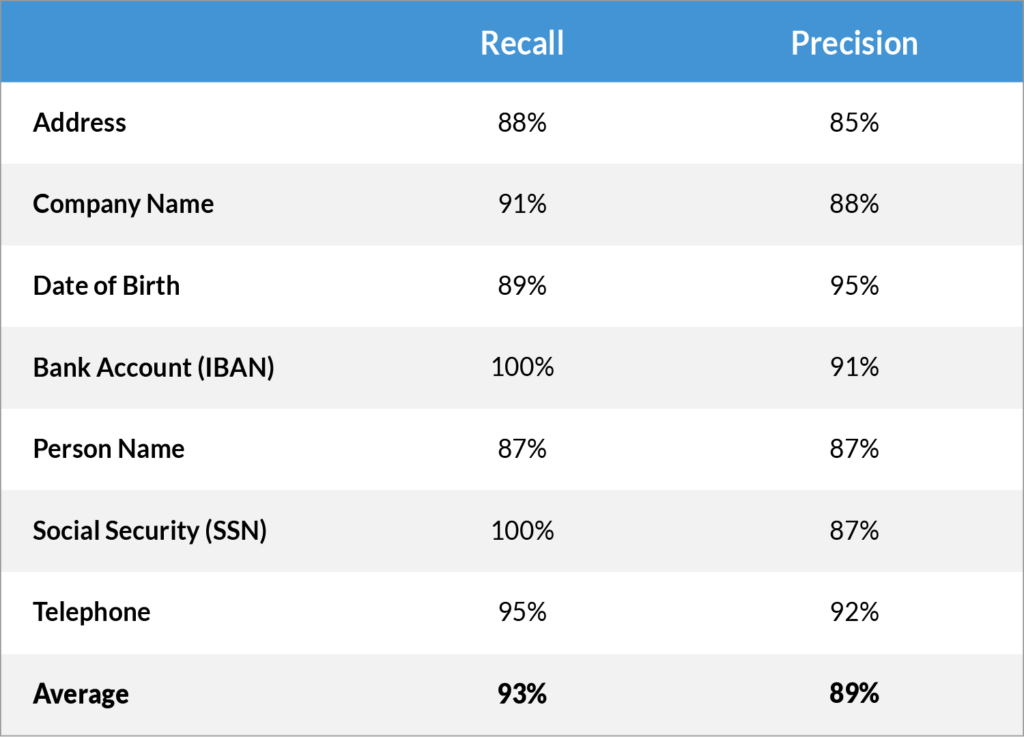
Let’s have a closer look at this experiment…
The results show that the recall is very high, with an average recall of 93%. As mentioned previously, for redaction, high recall is the key objective (making sure that the redaction finds as many as possible terms that need to be redacted).
Precision
However, recall alone is not the only key measure of a model’s accuracy, “precision” also needs to be considered. Precision is a measure of how many False Positives are generated(or better how few, since high Precision means low False Positives). In other words, how many terms are redacted that should not have been redacted. We touched upon this in our January blog post, but did not go into detail. Here we will go a bit deeper.
First of all, note that it is very easy to achieve a very high recall when we allow Precision to be very low. To illustrate that, consider this thought experiment:
If we redact everything in a document, every single word and number, the recall is guaranteed to be 100%, right? But the result is also useless, obviously. You could just as well have deleted the document.
That is an extreme case of course but, even with the most accurate AI tech, perfect recall and perfect precision cannot be achieved at the same time.
With our LLM-driven redaction tool, we aim to optimise recall, while still achieving a high level of Precision.
As a result, we typically get a recall of well over 90%, with a lower precision, but still of around 80-90% (in the example above it is on the higher end of that range).
How to deal with that In Practice
So, what does this mean for you in practice? Let’s take the lower end of the range, 80% precision: this would mean that of all redacted terms, 20% should not have been redacted. Sound like a lot? Well, it is not really. Suppose 5% of the terms (words, numbers, etc.) in a document need to be redacted (and in practice it is probably much less for most docs), it means that only about 1% of the words in the document are redacted that should not have been redacted*. That will hardly make the document unreadable.
That said, even those erroneously redacted words can be easily removed, with the right tools. More about that in our blog post next week.
Stay tuned…
Conclusion
AI redaction can save you an enormous amount of time and avoid human error. But it has to be AI redaction that really works: AI redaction that is accurate. As discussed in our blog post of 2 weeks ago, traditional automation techniques don’t work. And as discussed in last week’s blog post, the only way to achieve high accuracy is via AI based on Large Language models.
Are you looking for a VDR with fully integrated redaction software which leverages AI? Speak to our sales team or check out our Smart Redaction page here.
* 5% x 20%/80% = 1.25%


