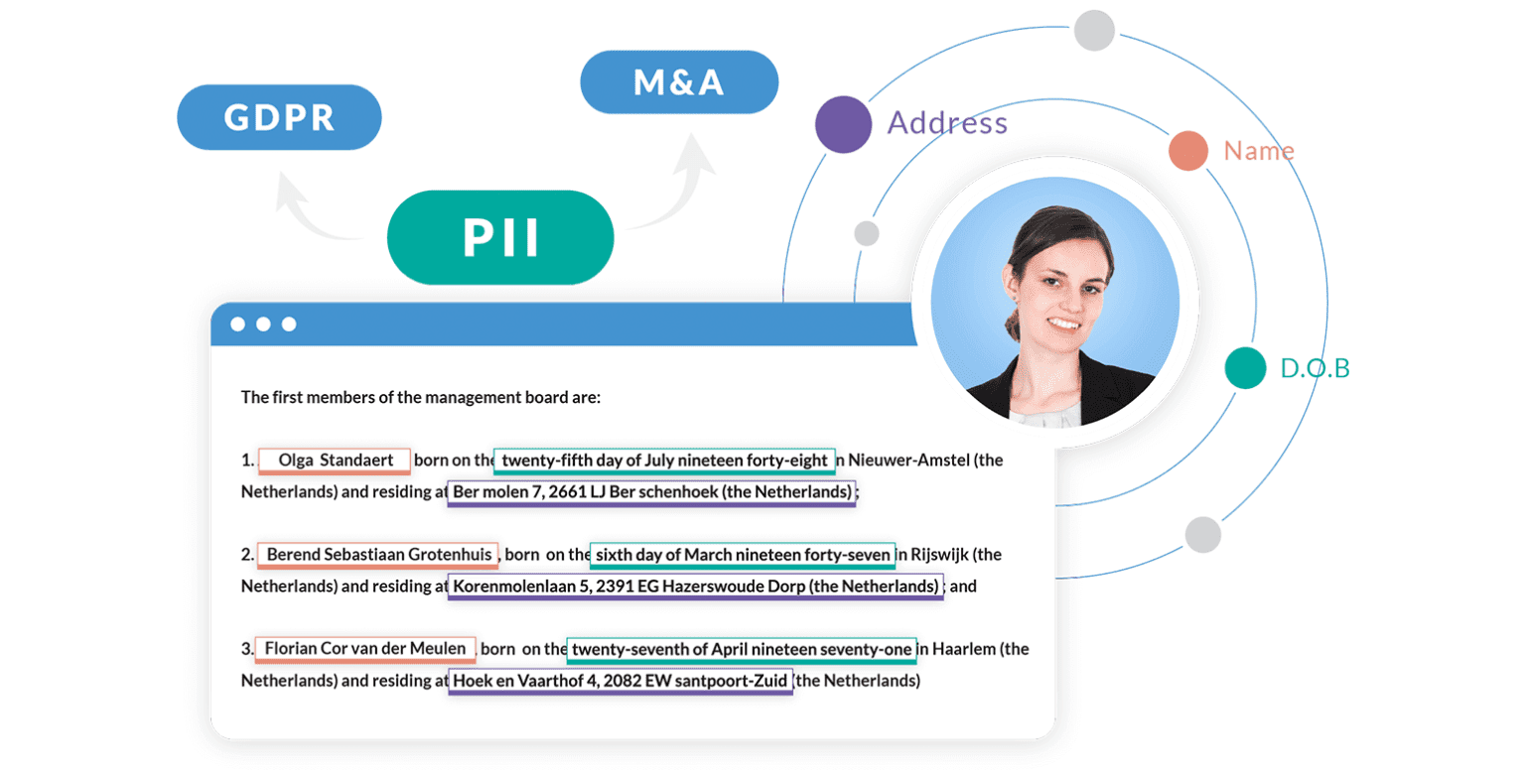
Why PII redaction is difficult (until now!)
Redacting Personal Identifiable Information (PII) is a necessity nowadays, to be GDPR compliant, and to protect Personal Data in an M&A setting.
Redacting PII data seems like a simple task, and one that one would think could be easily automated with software that makes use of a combination of searches and some simple rules (regular expressions). Unfortunately, that is not true, and as a result, making sure that documentation is properly redacted in practice still needs to be done manually.
And that is very time-consuming, expensive, and error-prone.
Introducing Imprima Smart Compliance
Here we introduce Smart Compliance, a new method that is indeed able to automate the process, with an AI-based method, that works in virtually any language, fully automated, with an accuracy that exceeds human redaction.
Fully automated, in virtually any language, with higher accuracy than manual? How is that possible, you may ask.
Well, we won’t go into the details in this post, but in essence, it is a trained Neural Network (So Machine Learning) that is able to understand relationships between linguistically related languages, so that if it is trained in a few languages, it can predict in many others, while increasing accuracy because it uses all languages it is trained in to predict in any language.
OK, whatever, you may think now. And indeed, it does not matter how the algorithm works. What does matter is how it performs.
In other words, the proof of the pudding is in the eating. So, what are the results? What we have seen from tests on our data is that accuracy (Recall) as high as 99-100% can be achieved. And that is actually more accurate than manual redaction, in practice, as we have seen on the same data sets.
Real-life example of redacting 30,000 words dataset
Here we show some statistics of redacting a set of client documents, containing ca. 30.000 words and other terms (dates, etc). These docs were manually redacted diligently, first by an Imprima person, and then QA-ed by the client, resulting in an accuracy that is above normal. Then we applied Smart Compliance.
NB: we did that without using these redactions as train data, as that would be cheating. These were the results of Smart Compliance vs. Manual redaction:
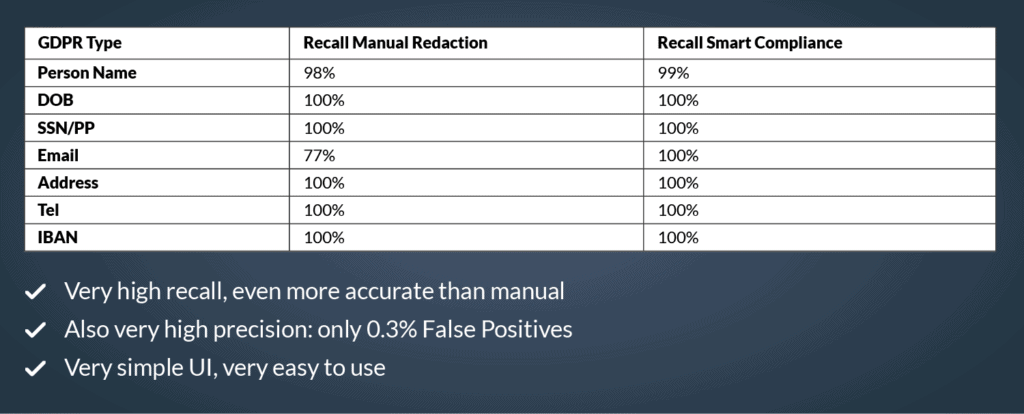
So, what do we see:
- Accuracy (Recall) of 99% to 100% indeed
- Even more accurate than high-quality, QA-ed, manual redaction
Not shown in the table, nevertheless making sure you know all the facts: some words were “over redacted” (false positives), but only very few: only 0.3% of all the words. That is going to hardly influence the readability of the document, so you could just leave them in. But if you want to remove, these redactions are easily identified and removed with Imprima Redaction.
And all that was achieved by essentially hitting a button. Fully automated, right out of the box (no training required).
How much time can you save?
This will obviously save you a lot of time, we believe as much as 90%, cutting down the manual effort involved to as much as one-tenth of full manual redaction.
We come to that number by assuming that you would like to manually inspect say a randomly picked subset of 10% of the documents, to make sure that the algorithm has performed well on all types of documents and no additional training data is required.
Who can use this tool?
Smart Compliance is now implemented as a function within the Imprima VDR and is also available as a standalone tool. We are now applying Smart Compliance to a range of customer data, including top-tier international law firms and the Big 4. The results confirm our testing.
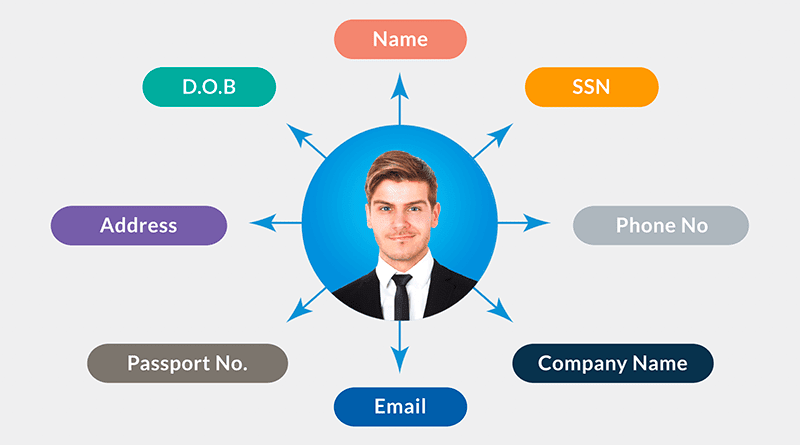
We believe this tool is a game-changer for any company that wants all PII data, including Individual’s name, Date of birth, Email, Address, Company name, Telephone number, Passport number, Social Security number, and IBAN to be protected for any reason, with a high degree of accuracy (more accurate than manual), and without the hassle and effort.


