
In our previous post “Should we blindly trust AI?”, we discussed the main benefit of an accurate AI tool for information extraction. And that is that it saves the user time, and not that it takes the human out of the loop.
At Imprima we like to be open about how accurate AI can be. Here we share the results from our latest tests.
For this experiment, we had a test set of legal documents, which contained 40 different data points (By “data points” we mean pieces of key information such as clauses, names and dates, such as: effective date, expiration date, anti-assignment, governing law, exclusivity, non-compete, change of control etc.).
We extracted these datapoints with Imprima’s Smart Summaries tool.
Here we show the test results for a selection of data points:
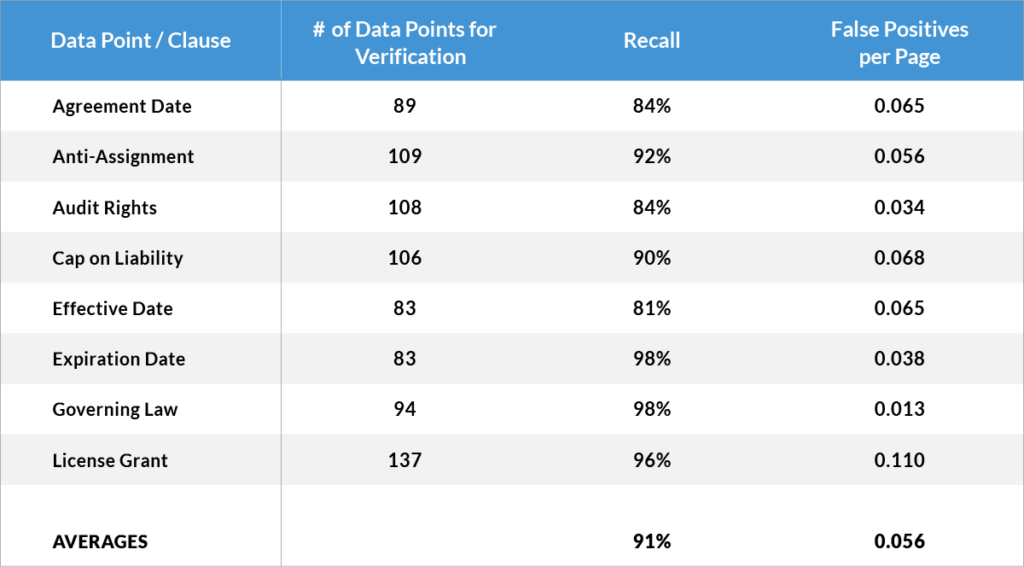
The main take aways from these test results are:
- A very high recall – over 90% on average – is achieved for these data points (as we have discussed in a previous blog post, that is higher than with manual information extraction).
- The number of false positives is very low (ca. 0.05 False Positives per document on average, in other words only 1 False Positive for every 20 pages).
Discarding such a low number of false positives wouldn’t take long, especially since the user doesn’t have to search for them. All extracted data points have been identified and highlighted by the Smart Summaries tool and the user will be able to jump directly to them and discard the few incorrect ones.
And as said, the real goal of high accuracy is to save time, and not to take the human out of the loop (and don’t trust any claims that a human in the loop is not necessary for any AI tool to be used to extract and classify information from legal and other documentation).
If you are interested in learning more about how Imprima’s AI tool can help with extracting key information from documents, visit the Smart Summaries product page, or contact us for a demo.


